
Scientific computing, and for that matter all of high-performance computing, is quickly migrating to GPU acceleration. Because clock speed is no longer scaling, but computing bandwidth continues to scale, computing algorithms written for single-instruction, multiple data (SIMD) architectures have been and will continue to scale along with Moore’s Law. Both GPU-accelerated algorithms and CPU-only algorithms utilize coarse-level parallelization by dividing the chip or mask data into partitions, and computing the partitions in CPU cores or CPU cores accelerated with GPU(s). But each computing unit computes much more data much faster with GPU acceleration. According to the figure below from NVIDIA, GPU computing continues to scale by bit width in contrast to CPU computing scaling by clock speed.

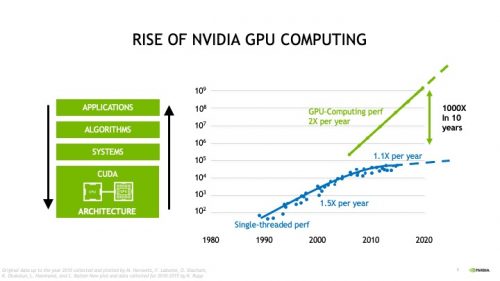
Optimal GPU acceleration is not the result of a simple replacement of GPUs for CPUs. To realize the >10X acceleration potential of GPU-based computing, you must understand when to deploy GPUs and when to use CPUs. The D2S GPU-acceleration approach employs sophisticated software engineering to combine the strength of each to the benefit of the whole system, deciding what to put on CPUs, what to put on GPUs, then scheduling and load-balancing the two to achieve optimal overall performance.
Below are some examples of the performance gains realized by D2S optimal GPU-acceleration when applied to common mask-making computations.








